
Medium
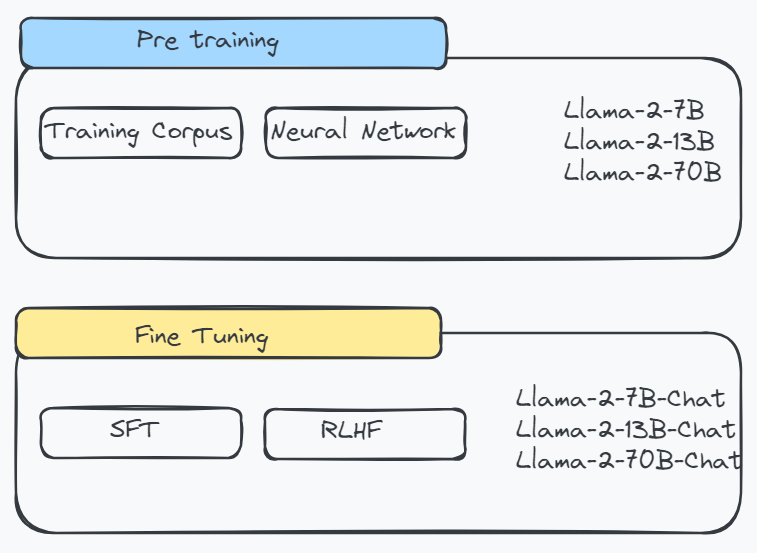
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. Llama 2 was pretrained on publicly available online data sources The fine-tuned model Llama Chat leverages publicly available instruction datasets and over 1 million human annotations. Llama 2 was pretrained on publicly available online data sources The fine-tuned model Llama Chat leverages publicly available instruction datasets and over 1 million human annotations. Meta developed and publicly released the Llama 2 family of large language models LLMs a collection of pretrained and fine-tuned generative text models ranging in. Llama 2 encompasses a range of generative text models both pretrained and fine-tuned with sizes from 7 billion to 70 billion parameters Below you can find and download LLama 2..
Agreement means the terms and conditions for use reproduction distribution and. Llama 2 is broadly available to developers and licensees through a variety of hosting providers and on the Meta website Llama 2 is licensed under the Llama 2 Community License. Metas license for the LLaMa models and code does not meet this standard Specifically it puts restrictions on commercial use for some users paragraph 2 and also restricts. Prohibited Uses We want everyone to use Llama 2 safely and responsibly You agree you will not use or allow others to use Llama 2 to Violate the law or others rights including to. With Llama 2 you can only use the generated dataset to improve Llama 2 Even for research purposes the license doesnt grant you..
%20(29).png)
Textcortex
The tutorial provided a comprehensive guide on fine-tuning the LLaMA 2 model using techniques like QLoRA PEFT. In this blog post we will discuss how to fine-tune Llama 2 7B pre-trained model using the PEFT library. Hà Hoàng 6mo ago 4529 views arrow_drop_up Copy Edit more_vert Llama 2 Fine-Tuning using QLora. It shows us how to fine-tune Llama 27B you can learn more about Llama 2 here on a small dataset. Learn how to fine-tune Llama 2 with LoRA Low Rank Adaptation for question answering. Solution overview Efficient Fine-tuning Llama2 using QLoRa The Llama 2 family of large language. Welcome to this Google Colab notebook that shows how to fine-tune the recent Llama-2-7b model on a single Google. To suit every text generation needed and fine-tune these models we will use QLoRA Efficient..
Code Llama 70B beats ChatGPT-4 at coding and programming 101 pm January 30 2024 By Julian Horsey Developers coders and those of you learning to program might be. Some of the main improvements of Llama 2 over the previous Llama are Llama 2 has 70 billion parameters which is more than twice the size of Llama which. Llama 2 and its dialogue-optimized substitute Llama 2-Chat come equipped with up to 70 billion parameters They undergo a fine-tuning process designed to align them closely. Llama 2 70b stands as the most astute version of Llama 2 and is the favorite among users We recommend to use this variant in your chat applications due to its prowess in. This release includes model weights and starting code for pretrained and fine-tuned Llama language models Llama Chat Code Llama ranging from 7B to 70B parameters..


Komentar